SQL语句 一种描述性语言
作用 对存储在RDBMS中的数据进行增删改查等操作
分类 数据控制语言 :DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK 对数据库安全性完整性等有操作的,可以简单的理解为权限控制或者事务操作等
数据定义语言 :DDL(Data Ddefinition Language) CREATE,DROP,ALTER 主要为以上操作 即对逻辑结构等有操作的,其中包括表结构,视图和索引。
数据查询语言 :DQL(Data Query Language)SELECT 查询操作,以select关键字。各种简单查询,连接查询等 都属于DQL。
数据操纵语言 :DML(Data Manipulation Language)INSERT,UPDATE,DELETE 对数据进行操作的,对应上面所说的查询操作 DQL与DML共同构建了多数初级程序员常用的增删改查操作。而查询是较为特殊的一种 被划分到DQL中。
官方文档 https://dev.mysql.com/doc/refman/8.0/en/sql-statements.html
DML INSERT - 插入 语法格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [(col_name [, col_name] ...)] { {VALUES | VALUE } (value_list) [, (value_list)] ... | VALUES row_constructor_list } [AS row_alias[(col_alias [, col_alias] ...)]] [ON DUPLICATE KEY UPDATE assignment_list] INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [AS row_alias[(col_alias [, col_alias] ...)]] SET assignment_list [ON DUPLICATE KEY UPDATE assignment_list] INSERT [LOW_PRIORITY | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [(col_name [, col_name] ...)] [AS row_alias[(col_alias [, col_alias] ...)]] {SELECT ... | TABLE table_name} [ON DUPLICATE KEY UPDATE assignment_list]
选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 value: {expr | DEFAULT} value_list: value [, value] ... row_constructor_list: ROW(value_list)[, ROW(value_list)][, ...] assignment: col_name = [row_alias.]value assignment_list: assignment [, assignment] ...
不做过多解释,参考官方文档
UPDATE - 修改 语法格式
单表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 UPDATE [LOW_PRIORITY ] [IGNORE ] table_reference SET assignment_list [WHERE where_condition] [ORDER BY ...] [LIMIT row_count ] value : {expr | DEFAULT } assignment: col_name = value assignment_list: assignment [, assignment] ...
多表
1 2 3 UPDATE [LOW_PRIORITY ] [IGNORE ] table_references SET assignment_list [WHERE where_condition]
官方文档
DELETE - 删除 单表语法
1 2 3 4 5 DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] FROM tbl_name [[AS ] tbl_alias] [PARTITION (partition_name [, partition_name] ...)] [WHERE where_condition] [ORDER BY ...] [LIMIT row_count ]
多表语法
1 2 3 4 5 6 7 8 9 DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] tbl_name[.*] [, tbl_name[.*]] ... FROM table_references [WHERE where_condition] DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] FROM tbl_name[.*] [, tbl_name[.*]] ... USING table_references [WHERE where_condition]
官方文档
DQL SELECT - 查询 语法格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY ] [STRAIGHT_JOIN ] [SQL_SMALL_RESULT ] [SQL_BIG_RESULT ] [SQL_BUFFER_RESULT ] [SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS ] select_expr [, select_expr] ... [into_option] [FROM table_references [PARTITION partition_list]] [WHERE where_condition] [GROUP BY {col_name | expr | position }, ... [WITH ROLLUP ]] [HAVING where_condition] [WINDOW window_name AS (window_spec) [, window_name AS (window_spec)] ...] [ORDER BY {col_name | expr | position } [ASC | DESC ], ... [WITH ROLLUP ]] [LIMIT {[offset ,] row_count | row_count OFFSET offset }] [into_option] [FOR {UPDATE | SHARE } [OF tbl_name [, tbl_name] ...] [NOWAIT | SKIP LOCKED ] | LOCK IN SHARE MODE ] [into_option]
关于排序:在MySQL 8.0.13之前,MySQL支持一个非标准的语法扩展,允许对GROUP BY列使用显式的ASC或DESC进行排序。MySQL 8.0.12及以后版本支持ORDER BY和分组函数,这样就不再需要使用这个扩展了。也就是说当使用GROUP BY时,可以对任意的一列或多列进行排序
公用表表达式 CTE(common table expression),MySQL8.0的新功能,是一个有命名的临时结果集,存在于单个语句的范围内,可以在该语句之后多次引用,可以理解为一个可以复用的子查询,CTE可以引用其他CTE,但子查询不能引用其他子查询,建议代替子查询
语法格式 1 2 3 WITH [RECURSIVE] cte_name [(col_name [, col_name] ...)] AS (subquery) [, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...
subquery
示例 以下出现的sql无任何具体意义,只为演示公用表表达式的使用
为了方便,以下公用表表达式全部使用 CTE 缩写代替
简单使用
1 2 3 WITH cte_1 AS (SELECT * FROM movies_channels_link WHERE channel_id=6) SELECT link_id,link_key FROM cte_1 ORDER BY cte_1.link_id DESC;
指定列
如果不显式声明 CTE 的列则使用subquery中查询出的列作为 CTE 的列名,显式声明了CTE的列则列的个数必须与subquery查询返回的列数量一样
1 2 3 WITH cte_1 (link_id1,link_key1) AS (SELECT link_id,link_key FROM movies_channels_link WHERE channel_id=6) SELECT * FROM cte_1 ORDER BY cte_1.link_id1 DESC;
定义多个表达式
1 2 3 4 5 WITH cte_1 (link_id,link_key) AS (SELECT link_id,link_key FROM movies_channels_link WHERE channel_id = 6), cte_2 (link_id,link_key) AS (SELECT link_id,link_key FROM movies_channels_link WHERE channel_id != 6) SELECT * FROM cte_1 JOIN cte_2 ORDER BY cte_1.link_id DESC;
递归CTE 递归cte是一种特殊的cte,其子查询会引用自身,with子句必须以 with recursive 开头
cte递归子查询包括两部分:seed 查询 和 recursive 查询,中间由union [all] 或 union distinct 分隔。
seed 查询会被执行一次,以创建初始数据子集
recursive 查询会被重复执行以返回数据子集,直到获得完整结果集。当迭代不会生成任何新行时,递归会停止
1 2 3 4 5 6 with recursive cte(n) as ( select 1 union all select n + 1 from cte where n < 10 ) select * from cte;
结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 -- 创建表 CREATE TABLE emp( id INT PRIMARY KEY NOT NULL, name VARCHAR(100) NOT NULL, manager_id INT NULL, INDEX (manager_id), FOREIGN KEY (manager_id) REFERENCES employees_mgr (id) ); -- 插入数据 INSERT INTO emp VALUES (333, "总经理", NULL), (198, "副总1", 333), (692, "副总2", 333), (29, "主任1", 198), (4610, "职员1", 29), (72, "职员2", 29), (123, "主任2", 692); -- 查询 WITH RECURSIVE test(id, name, path) AS ( SELECT id, name, CAST(id AS CHAR(200)) FROM emp WHERE manager_id IS NULL UNION ALL SELECT e.id, e.name, CONCAT(ep.path, ',', e.id) FROM test AS ep JOIN emp AS e ON ep.id = e.manager_id )SELECT * FROM test ORDER BY path;
结果:
1 2 3 4 5 6 7 8 9 10 11 +------+---------+-----------------+ | id | name | path | +------+---------+-----------------+ | 333 | 总经理| 333 | | 198 | 副总1| 333,198 | | 29 | 主任1| 333,198,29 | | 4610 | 职员1| 333,198,29,4610 | | 72 | 职员2| 333,198,29,72 | | 692 | 副总2| 333,692 | | 123 | 主任2| 333,692,123 | +------+---------+-----------------+
使用范围 以下可允许使用WITH子句
SELECT、UPDATE和DELETE语句的开头
1 2 3 WITH ... SELECT ... WITH ... UPDATE ... WITH ... DELETE ...
子查询(包括派生的表子查询)的开头
1 2 SELECT ... WHERE id IN (WITH ... SELECT ...) ... SELECT * FROM (WITH ... SELECT ...) AS dt ...
包含SELECT语句和SELECT for语句前面
1 2 3 4 5 6 INSERT ... WITH ... SELECT ... REPLACE ... WITH ... SELECT ... CREATE TABLE ... WITH ... SELECT ... CREATE VIEW ... WITH ... SELECT ... DECLARE CURSOR ... WITH ... SELECT ... EXPLAIN ... WITH ... SELECT ...
使用说明
同一级别只允许有一个WITH子句,如果声明多个 子句 需要在后面使用 , 分隔,一个语句可以包含多个 WITH
1 2 3 4 5 6 7 WITH cte1 AS (...) WITH cte2 AS (...) SELECT ... -- 这是非法的 同一级别只允许一个WITH子句, 需要改成下面这样 WITH cte1 AS (...), cte2 AS (...) SELECT ... -- 不同级别可以多个WITH子句 WITH cte1 AS (SELECT 1) SELECT * FROM (WITH cte2 AS (SELECT 2) SELECT * FROM cte2 JOIN cte1) AS dt;
CTE 的 subquery 就是一个正常的SQL语句,也可以使用变量和引用其他已经定义过的CTE等,引用的CTE必须是已经定义过的
给定查询块中的 CTE 可以引用在更外部级别的查询块中定义的CTE,但不能引用在更内部级别的查询块中定义的CTE。什么意思?如下解释
1 2 3 4 5 6 7 8 9 10 11 12 -- 以下成立 WITH cte1 AS (SELECT 1) SELECT * FROM ( WITH cte2 AS (SELECT 2) SELECT * FROM cte2 JOIN cte1 ) AS dt; -- 以下不成立,报错 Table 'test.cte2' doesn't exist,就是说cte2在内部查询中定义的不能在外部sql中使用 WITH cte1 AS (SELECT 1) SELECT * FROM ( WITH cte2 AS (SELECT 2) SELECT * FROM cte2 JOIN cte1 ) AS dt INNER JOIN cte2;
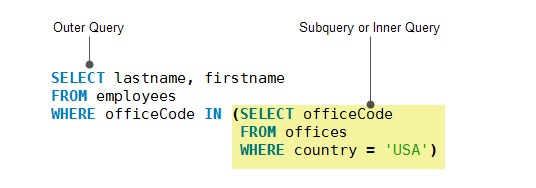
CTE 与子查询、派生表、临时表的对比 子查询 子查询是嵌套在另一个查询(如select、insert、update和delete)中的查询。子查询又称为内部查询,而包含子查询的查询称为外部查询。 子查询可以在使用表达式的任何地方使用,并且必须在括号中关闭
如下图所示
派生表 派生表是从select语句返回的虚拟表。派生表类似于临时表,但是在 SELECT 语句中使用派生表比临时表简单得多,因为派生表没有创建临时表的步骤。派生表会在使用过后即时清除的,所以我们在简化复杂查询的时候可以考虑使用。
1 2 3 SELECT column_list FROM ( SELECT column_list FROM table_1) derived_table_name --派生表 WHERE derived_table_name.c1 > 0;
注意:
派生表和子查询通常可以互换使用,但是与子查询不同的是,派生表必须具有别名
派生表之间不可以相互引用。例如:SELECT … FROM (SELECT … FROM …) AS d1, (SELECT … FROM d1 …) AS d2,第一个查询标记为d1,在第二个查询语句中使用d1是不允许的
临时表 临时表是一种特殊类型的表,使用CREATE TEMPORARY TABLE 创建,它允许您存储一个临时结果集,可以在单个会话中多次重用。
临时表操作
1 2 3 4 5 6 7 8 CREATE TEMPORARY TABLE table_name ( name VARCHAR (10 ) NOT NULL , value INTEGER NOT NULL ); drop temporary table table_name;
说明
当会话结束或连接终止时,MySQL会自动删除临时表。当您不再使用临时表时,也可以使用DROP TABLE 语句来显式删除临时表。
一个临时表只能由创建它的客户机访问。不同的客户端可以创建具有相同名称的临时表,而不会导致错误,因为只有创建临时表的客户端才能看到它。 但是,在同一个会话中,两个临时表不能共享相同的名称。
临时表可以与数据库中的普通表具有相同的名称。 不推荐使用相同名称。例如,如果在 test库中创建一个名为 temp 的临时表,则现有的 temp 表将变得无法访问。 对 temp 表发出的每个查询现在都是指 temp 临时表。 只有当删除 temp 临时表时,正常的 temp 表可以再次访问
比较 CTE VS 子查询
CTE VS 临时表
CET大部分地方可以代替临时表。CTE最优秀的地方是在实现递归操作,和替代绝大部分游标的功能
CET后面必须直接跟使用CTE的SQL语句(如select、insert、update等),否则,CET将失效。但是临时表一直存在,除非drop掉。
对于大数据量,由于CET不能建索引,所以性能会比临时表差。即使临时表不建索引性能也比CTE强,建议在数据量大的时候使用临时表
CTE VS 派生表
相对于派生表最主要的优势在于可以一次定义,多次使用