时序数据库
传统数据库仅仅记录数据的当前值,时序数据库记录了所有的历史数据
适用于依赖时间产生并且数据量非常大的数据,对数据的写入QPS和实时查询都要求非常高
一般用于IT基础设施、运维监控系统和物联网中
比如车辆行驶,可以记录每辆车每秒钟的所在位置来绘出车辆的整体行驶轨迹,还可以计算在每个位置的停留时间等等
虽然clickhouse也支持时序数据,但感觉总归是没有专门用来处理这一情况的influxdb专业,暂未得到验证
特性
- 支持类似SQL的查询语法
- 提供了Http Api直接访问
- 存储超过10亿级别的时间序列数据
- 灵活的数据保留策略,可以定义到Database级别(只保留最热的数据)
- 内置管理接口和CMD
- 飞一般速度的聚合查询
- 按不同时间段进行聚合查询
- 内置持续查询功能,定时计算指定时间段的数据,插入到指定表中,可以理解为定时归集数据
- 水平扩展,支持集群模式(收费)
缺点
只有单机版是免费开源的,集群版本是要收费的
存在前后版本兼容问题,1.x和2.0版本区别较大
使用场景
时序数据库的应用场景
IT基础设施
运维监控系统
物联网
测试
InfluxData
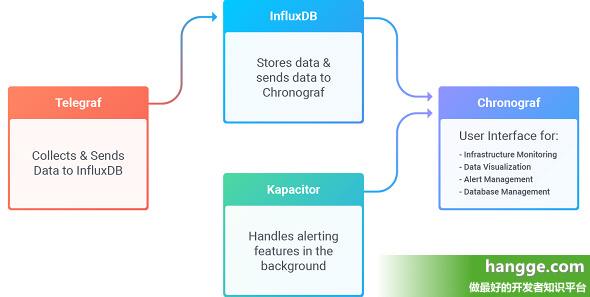
TICK 与 InfluxDB
TICK 是 InfluxData 平台的组件集的缩写,分别代表四大组件:Telegraf(数据收集器)、InfluxDB(时序数据库)、Chronograf(可视化 UI)和 Kapacitor(监控服务)。
InfluxData 公司的愿景是帮助人们处理时序数据,仅依靠一个时序数据库是不够的,还需要解决因为时序数据自身产生的一系列问题。因此 InfluxData 决定设计并开发 TICK。
在早期 Kapacitor 的脚本语言是 TICKScript,但是并不好用,遭受到社区中很多人的诟病。因此出现了 Flux。Flux 的功能性比 InfluxQL 更强,比 TICKScript 更易用。
随着 Flux 的逐渐发展,InfluxDB 的能力范围也在逐步扩展
InfluxDb重要概念
database:库。需要提前创建
measurement:表。不需要提前创建
tag:标签。
维度列,tags相当于SQL中的有索引的列,是可选的,但是强烈建议使用。- tag set:每组标签的集合,每组tag key 和tag value的集合
- tag key -> tag value :标签标识 -> 标签值。
tag value只能是string类型
- tag key -> tag value :标签标识 -> 标签值。
- tag set:每组标签的集合,每组tag key 和tag value的集合
filed:字段,列。
与tags相反,fileds相当于SQL中没有索引的列,但是必须存在。字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值- filed set:每组字段的集合,每组filed key 和filed value 的集合
- filed key -> filed value:字段标识 -> 字段值。
field value可以为string,float,integer或boolean类型。field value通常都是与时间关联的
- filed key -> filed value:字段标识 -> 字段值。
- filed set:每组字段的集合,每组filed key 和filed value 的集合
tags一般用于不随时间变换而变化的属性、维度,比如主机监控中每台机器的标识列使用tags,而每秒钟机器的出入网流量值则用filed存储
timestamp :UTC时间戳
retention policy:数据存储策略。用于设置数据保留的时间,每个database刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。
InfluxDB 不提供直接删除数据的方法,但会根据数据存储策略定期清除过期的数据。series:在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
series 的 key 为 measurement + 所有 tags 的序列化字符串,这个 key 在之后会经常用到
point:series + timestamp 可以用于区别一个 point,也就是说一个 point 可以有多个 field name 和 field value
InfluxQL
注意:
在InfluxDB 1.x中,数据存储在数据库 和保留策略中。在InfluxDB OSS 2.0中,数据存储在存储桶中。由于InfluxQL使用1.x数据模型,因此在InfluxQL中进行查询之前,必须将存储桶映射到数据库和保留策略(DBRP)。具体操作文档:使用InfluxQL查询数据| InfluxDB OSS 2.0文档 (influxdata.com)
InfluxDB OSS 2.0支持InfluxQL只读查询。请参阅下面的受支持和不受支持的查询

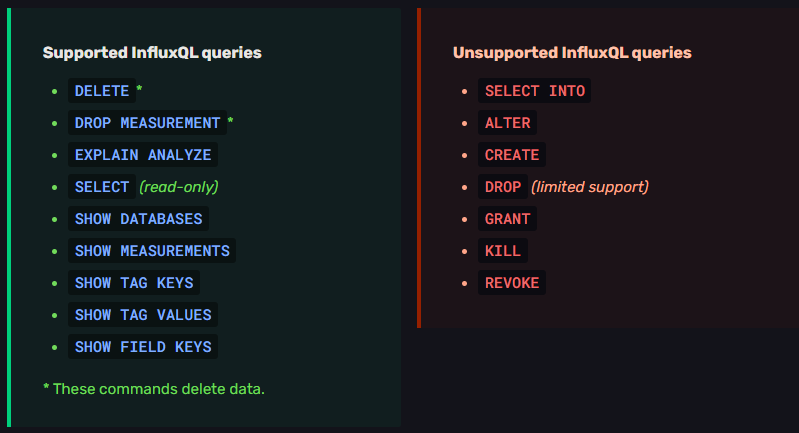
库表操作
官方文档:Manage your database using InfluxQL | InfluxDB OSS 1.8 Documentation (influxdata.com)
支持的操作

1 | -- 创建数据库 |
influx命令行导入数据
1 | influx -import -path=NOAA_data.txt -precision=s -database=NOAA_water_database |
数据文件格式:
1 | # DDL |
首先创建了一张表
后面为要导入的数据,每一行为一条数据
h20_feet为表名
location 为tag_key ,coyote_creek为tag_value
注意空格
water_level和level description 为filed_key,注意level后面的空格为转义的
8.120和between 6 and 9 feet为filed_value
注意空格
时间戳
数据操作
官方文档:Explore data using InfluxQL | InfluxDB OSS 1.8 Documentation (influxdata.com)
支持的操作

插入数据
1 | insert test,host=127.0.0.1,monitor_name=test count=1 |
查询数据
1 | -- 查看当前数据库每个表中的字段 |
删除数据
1 | -- 删除表所有数据,则表就不存在了 |
函数
官方文档:InfluxQL functions | InfluxDB OSS 1.8 Documentation (influxdata.com)
支持的函数列表
聚合函数
| 函数 | 作用 |
|---|---|
| COUNT() | 统计数量 |
| DISTINCT() | 去重 |
| INTEGRAL() | 求[定积分](定积分_百度百科 (baidu.com)) |
| MEAN() | 求算术平均值 |
| MEDIAN() | 字段的中间值 |
| MODE() | 字段中最常出现的值 |
| SPREAD() | 返回字段最大与最小值之间的差值 |
| STDDEV() | 字段值的标准偏差 |
| SUM() | 求和 |
选择函数
| 函数 | 作用 |
|---|---|
| BOTTOM() | 返回列中最小的N个值 |
| FIRST() | 按照timestamp排序返回列中最旧的值 |
| LAST() | 按照timestamp排序返回列中最新的值 |
| MAX() | 返回列中最大的值 |
| MIN() | 返回列中最小的值 |
| PERCENTILE() | 返回列中第N个百分位数 |
| SAMPLE() | 返回字段 n个值的随机样本。 Sample()使用储库采样来生成随机点 |
| TOP() | 返回列中最大的N个值 |
转换函数
| 函数 | 作用 |
|---|---|
| ABS() | 绝对值 |
| ACOS() | 返回字段值的反余弦的值,字段值在-1到1之间 |
| ASIN() | 返回字段值的反正弦的值,字段值在-1到1之间 |
| ATAN() | |
| ATAN2() | |
| CEIL() | |
| COS() | |
| CUMULATIVE_SUM() | |
| DERIVATIVE() | |
| DIFFERENCE() | |
| ELAPSED() | |
| EXP() | |
| FLOOR() | |
| HISTOGRAM() | |
| LN() | |
| LOG() | |
| LOG2() | |
| LOG10() | |
| MOVING_AVERAGE() | |
| NON_NEGATIVE_DERIVATIVE() | |
| NON_NEGATIVE_DIFFERENCE() | |
| POW() | |
| ROUND() | |
| SIN() | |
| SQRT() | |
| TAN() |
预测因子函数
| 函数 | 作用 |
|---|---|
| HOLT_WINTERS() |
技术分析函数
| 函数 | 作用 |
|---|---|
| CHANDE_MOMENTUM_OSCILLATOR() | |
| EXPONENTIAL_MOVING_AVERAGE() | |
| DOUBLE_EXPONENTIAL_MOVING_AVERAGE() | |
| KAUFMANS_EFFICIENCY_RATIO() | |
| KAUFMANS_ADAPTIVE_MOVING_AVERAGE() | |
| TRIPLE_EXPONENTIAL_MOVING_AVERAGE() | |
| TRIPLE_EXPONENTIAL_DERIVATIVE() | |
| RELATIVE_STRENGTH_INDEX() |
连续查询
连续查询(CQ)是在实时数据上自动和定期运行的fluxql查询,并在指定的度量中存储查询结果
官方文档:InfluxQL Continuous Queries | InfluxDB OSS 1.8 Documentation (influxdata.com)
数据采集
无开发
Telegraf 采集
influxdata开源的数据采集器,Telegraf是一个插件驱动的服务器代理,用于收集和报告指标,是TICK堆栈的第一块。Telegraf有插件可以直接从它运行的系统获取各种指标,从第三方api获取指标,甚至通过statsd和Kafka消费者服务监听指标。它也有输出插件来发送度量到各种其他数据存储、服务和消息队列,包括fluxdb、石墨、OpenTSDB、Datadog、Librato、Kafka、MQTT、NSQ等。
官方文档:Telegraf 1.18 Documentation (influxdata.com)
数据采集器
fluxdb scraper定期从指定的目标收集数据,然后将收集到的数据写入一个fluxdb桶。scraper可以从任何HTTP(S)可访问的端点收集数据,这些端点以Prometheus数据格式提供数据。
第三方
许多第三方技术可以配置为直接发送线路协议到fluxdb。
- (Write metrics and log events only) Vector 0.9 or later:一个开源的主机监控框架
- Apache NiFi 1.8 or later:是一个易于使用、功能强大而且可靠的数据处理和分发系统
- OpenHAB 3.0 or later:开放家庭自动化总线,是一个开源的、不依赖技术的家庭自动化平台
- Apache JMeter 5.2 or later:一个用于加载功能行为和度量性能的开源测试工具
- FluentD 1.x or later:用于统一日志层的开源数据收集器
开发者工具
开发语言的客户端库
Flux导入CSV数据
Flux:facebook开源,使用单向数据流的React的应用程序架构
influx WriteCommand 导入CSV数据

influxQL语句插入



