OLTP和OLAP OLTP 联机事务处理
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合
OLAP特征
绝大多数是读请求
数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
已添加到数据库的数据不能修改。
对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
宽表,即每个表包含着大量的列
查询相对较少(通常每台服务器每秒查询数百次或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
事务不是必须的
对数据一致性要求低
每个查询有一个大表。除了他以外,其他的都很小。
查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
区别
OLTP
OLAP
主要使用场景
在线业务服务
数据分析、挖掘、机器学习
涉及数据量
当前正在发生的业务数据
历史存档数据,时间跨度可能比较大
事务和数据完整性
对事务和数据一致性要求比较高
对事务能力没有要求,数据不一致也能重建数据
功能使用需求
简单的增删改查,要求响应时间极端(ms)
复杂的聚合和多数据源关联;查询执行时间可到分钟、小时、天级别
并发要求
高并发
低并发
技术实现方案
事务、索引、存储计算在一起
大量SCAN,列式存储,存储计算可以分开
可用性要求
非常高
要求不高
数据模型 / 规范
关系模型、3NF范式
维度模型,关系模型,对范式要求极低
技术典范
MySQL,Oracle
SQL-On-Hadoop
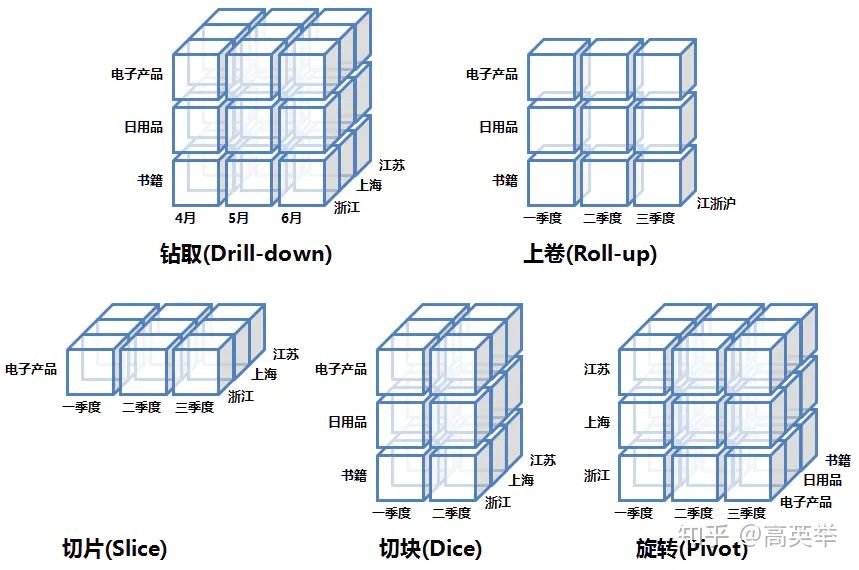
OLAP引擎的常见操作
上卷(Roll Up)/聚合:选定某些维度,根据这些维度来聚合事实,如果用SQL来表达就是select dim_a, aggs_func(fact_b) from fact_table group by dim_a.
下钻(Drill Down):上卷和下钻是相反的操作。它是选定某些维度,将这些维度拆解出小的维度(如年拆解为月,省份拆解为城市),之后聚合事实。
切片(Slicing、Dicing):选定某些维度,并根据特定值过滤这些维度的值,将原来的大Cube切成小cube。如dim_a in (‘CN’, ‘USA’)
旋转(Pivot/Rotate):维度位置的互换。
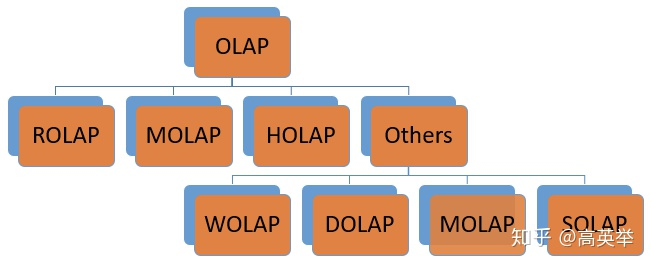
OLAP分类
ROLAP:关系型 OLAP ( Relational OLAP )
典型代表是:Presto,Impala,GreenPlum,Clickhouse,Elasticsearch,Hive,Spark SQL,Flink SQL
数据写入时,ROLAP并未使用像MOLAP那样的预聚合技术;ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
优点: ROLAP 不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。
缺点: 当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
因此,ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
MOLAP:多维 OLAP ( Multi-dimensional OLAP )
典型代表是:Druid,Kylin,Doris
一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据,Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显
优点: 数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的及时计算,提升了查询性能。
缺点: 这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)
因此,MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析
*HOLAP:混合 OLAP ( Hybrid OLAP ) *
混合 OLAP,是 MOLAP 和 ROLAP 的一种融合。当查询聚合性数据的时候,使用MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。
国内外有一些闭源的商业OLAP引擎,使用的公司不多并且源码不可见、资料少,很难分析学习其中的源码和技术点。在一二线的互联网公司中,应用较为广泛的还是上面提到的各种OLAP引擎
传统数仓与离线计算的弊端
时效性低
对于音乐服务来说,实时下钻和分析PV、UV,用户圈层、歌曲的种类、DAU等数据,分析结果的价值取决于时效性。核心日报与统计报表场景下,基于Hive的离线分析仅能满足T+1的时效,对于实时日报和分析的需求越来越强烈。
易用性低
基于Hive离线数据分析平台,对于产品、运营、市场人员具有较高的技术门槛,无法满足自助的实时交互式分析需求;开发在上报和提取分析数据时,无法实时获取和验证结果,查询和分析日志经常需要几个小时。
流程效率低
数据分析需求,需由数据分析团队完成,经过排期、沟通、建模、分析、可视化等流程步骤,所需时间以周计算,落地可能达数周,分析结果不及时,影响和拖慢了决策进度。
为了应对以上问题,提升流程效率,提高数据分析处理的时效性和易用性,数据的即席分析和数据可视化 能力支撑需要优化和提升,让问题秒级有响应,分析更深入,数据分析更高效。
ClickHouse 特性
真正的面向列的DBMS。(ClickHouse是一个DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置和重新启动服务器)
数据压缩。(一些面向列的DBMS(INFINIDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实是提高了性能)
磁盘存储的数据。(许多面向列的DBMS(SPA HANA和GooglePowerDrill))只能在内存中工作。但即使在数千台服务器上,内存也太小了。)
多核并行处理。(多核多节点并行化大型查询)
分布式处理。(在clickhouse中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分片上并行处理)
SQL支持。(ClickHouse sql 跟真正的sql有不一样的函数名称。不过语法基本跟SQL语法兼容,支持JOIN/FROM/IN 和JOIN子句及标量子查询支持子查询)
向量化引擎。(数据不仅按列式存储,而且由矢量-列的部分进行处理,这使得开发者能够实现高CPU性能)
实时数据更新。(ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序。由于这个原因,数据可以不断地添加到表中)
支持近似计算。(统计全国到底有多少人?143456754 14.3E)
数据复制和对数据完整性的支持。(ClickHouse使用异步多主复制。写入任何可用的复本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复)
缺点
没有完整的事务支持,不支持Transaction,想快就别Transaction
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询
缺少完整的Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅用于批量删除或修改数据
聚合结果必须小于一台机器的内存大小
支持有限操作系统,正在慢慢完善
不适合Key-value存储,不支持Blob等文档型数据库
并发能力低,建议1000左右并发使用,数据量太大最多支持100
使用场景 ClickHouse对大数据量的聚合分析处理速度很快,但并发能力很低,建议1000左右并发使用,数据量太大最多支持100
适用场景
web和app数据分析
广告网络和RTB
电信
电子商务和金融
信息安全
监测
时序数据
商业智能
在线游戏
物联网
不适用场景
事务性工作(OLTP)
高并发的键值访问
文档存储
超标准化的数据
行业用户及使用场景
ClickHouse用户 | ClickHouse文档
测试 测试服务器配置 2核4G
使用官方测试数据
数据说明
visits_v1:1679791。预先构建的会话
hits_v1:8873898 。所有用户在服务所涵盖的所有网站上完成的每个操作
导入三次数据:总数据量 三千五百万
导入文件数据 1 2 clickhouse-client --query "INSERT INTO tutorial.hits_v1 FORMAT TSV" --max_insert_block_size=100000 < hits_v1.tsv clickhouse-client --query "INSERT INTO tutorial.visits_v1 FORMAT TSV" --max_insert_block_size=100000 < visits_v1.tsv
插入块最大为100000 ,两个为200000
两个文件总大小 9.8G
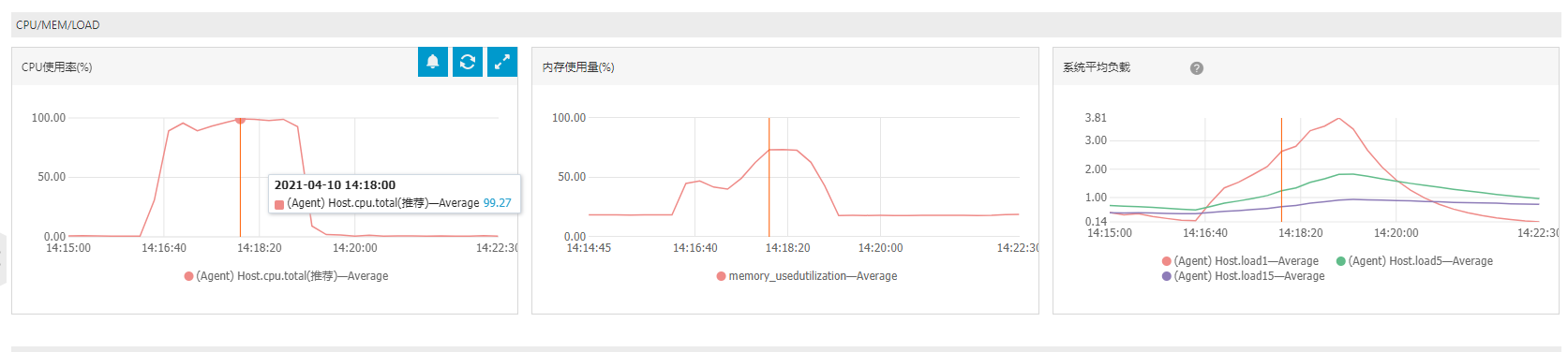
cpu、内存和负载
磁盘读写
查询 所有的查询都在本机clickhouse-client执行,排除了网络传输导致查询慢的因素
单机
visits_v1 5037815数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 SELECT * FROM visits_v1 LIMIT 1 ;SELECT * FROM visits_v1 hv where UserID = '417958942509176083' ;SELECT * FROM visits_v1 WHERE StartDate BETWEEN '2014-03-23' AND '2014-03-30' ORDER BY StartDate DESC LIMIT 100 ;SELECT CounterID,StartDate,Sign ,IsNew,LinkURL,StartURL,EndURL FROM visits_v1 WHERE StartDate BETWEEN '2014-03-23' AND '2014-03-30' ORDER BY StartDate DESC LIMIT 100 ;SELECT StartURL AS URL , AVG (Duration ) AS AvgDuration FROM tutorial.visits_v1WHERE StartDate BETWEEN '2014-03-23' AND '2014-03-30' GROUP BY URL ORDER BY AvgDuration DESC LIMIT 10 SELECT sum (Sign ) AS visits, sumIf(Sign , has(Goals.ID, 1105530 )) AS goal_visits, (100. * goal_visits) / visits AS goal_percent FROM tutorial.visits_v1WHERE (CounterID = 912887 ) AND (toYYYYMM(StartDate) = 201403 ) AND (domain (StartURL) = 'yandex.ru' )
hits_v1 29121694数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 SELECT * FROM hits_v1 LIMIT 1 ;SELECT * FROM hits_v1 hv where WatchID = '8091123540819861613' ;SELECT * FROM hits_v1 WHERE EventDate BETWEEN '2014-03-23' AND '2014-03-30' ORDER BY EventDate DESC LIMIT 100 ;SELECT EventDate,Title,CounterID,ClientIP,ClientIP6,RegionID,UserID,OS,UserAgent,URL ,Referer,IsRobot,IsLink FROM hits_v1 WHERE EventDate BETWEEN '2014-03-23' AND '2014-03-30' ORDER BY EventDate DESC LIMIT 100 ;SELECT Title AS TITLE, AVG (Age) AS AvgAge FROM tutorial.hits_v1 hv WHERE EventDate BETWEEN '2014-03-23' AND '2014-03-30' GROUP BY TITLEORDER BY TITLE DESC LIMIT 10 ;SELECT sum (HTTPError) AS HTTPError1, COUNT (1 ) AS goal_visits, (100. * goal_visits) / SUM (Age) AS goal_percent FROM tutorial.hits_v1 hv WHERE (WatchID = '8091123540819861613' ) AND (toYYYYMM(EventDate) = 201403 ) AND (domain (URL ) = 'webmodelka' )
联表
1 2 3 4 5 6 7 8 9 10 SELECT vv.ClickURL, COUNT (1 ),COUNT (DISTINCT UserID)FROM visits_v1 vv LEFT JOIN hits_v1 hv ON vv.UserID = hv.UserID WHERE vv.ClickEventTime BETWEEN '2014-03-23' AND '2014-03-24' AND (domain (vv.ClickURL) = 'autor.in' )GROUP BY domain (hv.URL), vv.ClickURL;
模拟线上数据进行测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 CREATE TABLE tutorial.sr_partner_used_minute ( partner_code UInt32, resource_id UInt16, resource_code String , resource_name String , idc_id UInt16, idc_name String , idc_area_id UInt8, idc_area_name String , total_servers UInt32, online_servers UInt32, restart_servers UInt32, used_servers UInt32, date_time DateTime, created_time DateTime, update_time DateTime ) ENGINE =MergeTree() PARTITION BY toDate(date_time)ORDER BY (date_time, idc_id, partner_code, resource_id);
导入数据
1 insert into tutorial.sr_partner_used_minute (partner_code, resource_id, resource_code, resource_name, idc_id, idc_name, idc_area_id, idc_area_name, total_servers, online_servers, restart_servers, used_servers, date_time, created_time, update_time) SELECT partner_code, resource_id, resource_code, resource_name, idc_id, idc_name, idc_area_id, idc_area_name, total_servers, online_servers, restart_servers, used_servers, date_time, created_time, update_time FROM mysql('rm-bp19100z6qiyx8j43125090.mysql.rds.aliyuncs.com:3306' , 'dsom_service_datas' , 'sr_partner_used_minute_2021_03' ,'dataquantmgr' , 'DaLQng_dataquant' )
累加数据
1 insert into tutorial.sr_partner_used_minute (partner_code, resource_id, resource_code, resource_name, idc_id, idc_name, idc_area_id, idc_area_name, total_servers, online_servers, restart_servers, used_servers, date_time, created_time, update_time) SELECT partner_code, resource_id, resource_code, resource_name, idc_id, idc_name, idc_area_id, idc_area_name, total_servers, online_servers, restart_servers, used_servers, date_time, created_time, update_time FROM tutorial.sr_partner_used_minute;
测试
130w数据执行线上sql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT idc_name,partner_code,resource_name,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name,date_time ORDER BY rate_online DESC , date_time DESC LIMIT 1000 OFFSET 1000 ;SELECT CONCAT (toString(partner_code),'--' , idc_name) AS partner_idc,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY partner_idc, date_time ORDER BY date_time,partner_idc ASC ;SELECT idc_name,partner_code,resource_name,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name ORDER BY rate_used DESC LIMIT 3 ;
500w
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT idc_name,partner_code,resource_name,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name,date_time ORDER BY rate_online DESC , date_time DESC LIMIT 1000 OFFSET 1000 ;SELECT CONCAT (toString(partner_code),'--' , idc_name) AS partner_idc,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY partner_idc, date_time ORDER BY date_time,partner_idc ASC ;SELECT idc_name,partner_code,resource_name,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name ORDER BY rate_used DESC LIMIT 3 ;
1000w
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT idc_name,partner_code,resource_name,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name,date_time ORDER BY rate_online DESC , date_time DESC LIMIT 1000 OFFSET 1000 ;SELECT CONCAT (toString(partner_code),'--' , idc_name) AS partner_idc,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY partner_idc, date_time ORDER BY date_time,partner_idc ASC ;SELECT idc_name,partner_code,resource_name,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name ORDER BY rate_used DESC LIMIT 3 ;
5000w
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT idc_name,partner_code,resource_name,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name,date_time ORDER BY rate_online DESC , date_time DESC LIMIT 1000 OFFSET 1000 ;SELECT CONCAT (toString(partner_code),'--' , idc_name) AS partner_idc,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY partner_idc, date_time ORDER BY date_time,partner_idc ASC ;SELECT idc_name,partner_code,resource_name,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name ORDER BY rate_used DESC LIMIT 3 ;
1亿
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT idc_name,partner_code,resource_name,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name,date_time ORDER BY rate_online DESC , date_time DESC LIMIT 1000 OFFSET 1000 ;SELECT CONCAT (toString(partner_code),'--' , idc_name) AS partner_idc,SUBSTRING (toString(date_time), 1 , 13 ) AS date_time,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute spum WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY partner_idc, date_time ORDER BY date_time,partner_idc ASC ;SELECT idc_name,partner_code,resource_name,(SUM (online_servers) / SUM (total_servers)) * 100 AS rate_online, (SUM (restart_servers) / SUM (total_servers)) * 100 AS rate_restart, (SUM (used_servers) / SUM (total_servers)) * 100 AS rate_used FROM sr_partner_used_minute WHERE date_time BETWEEN '2021-03-01 00:00:00' AND '2021-03-31 23:59:59' AND idc_id != 0 GROUP BY idc_name,partner_code,resource_name ORDER BY rate_used DESC LIMIT 3 ;
结论:
clickhosue适合做宽表存储大量数据,但在查询时不建议获取所有列 ,只返回有效列
适合进行计算分析等操作,不适合大量查询数据记录
不适合点查,clickhouse的稀疏索引导致其在点查时的效率低下,查询时建议都带上分区键作为筛选条件
sql的执行效率会随着数据量的增长越来越低下
由于是单机进行的测试,如果是分布式集群的话sql效率应该会更高