此篇纯属误人子弟,MySQL的先到此为止,以后有兴趣再整理
什么是索引
索引是帮助MySQL高效获取数据的排好序的数据结构
作用类似于新华字典或者英语字典的检字表或者也叫索引的作用一样,按照一定顺序排好序的,可以很快定位到在某一页或者直接到某一行
索引数据结构
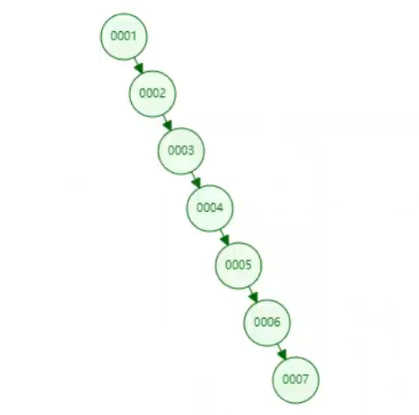
二叉树
在极端情况下,二叉树会变成链表,比如主键索引是递增的,在查找时无异于全表扫描

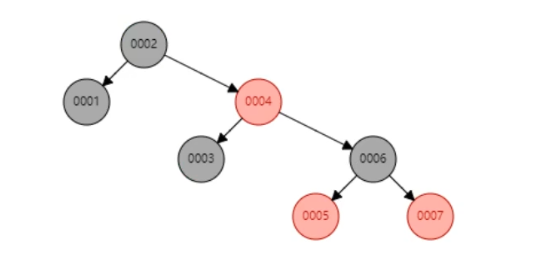
红黑树(二叉平衡树)
- 节点不是黑色就是红色
- 根必须是黑色节点
- 红色节点子节点必须是黑色节点
- 从根到叶子节点的路径上黑色节点数量必须相等,除此之外没有其他了
红黑树本身就没满足树的平衡规则,它是一种近似平衡的结构,它有它的一个平衡规则,对于红黑树来说只要从根到叶子节点经过相同数目的黑色节点它就认为是平衡的
问题:红黑树的高度不可控(高度=2log(n+1),n为节点数),当数据越来越多时,红黑树的高度会很高,在查找时扫描次数依然很多
Hash
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快
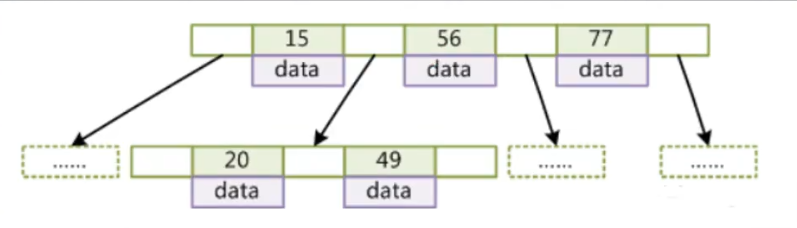
B-Tree(B树,不叫B-树)
- 叶子节点具有相同的深度,叶子节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
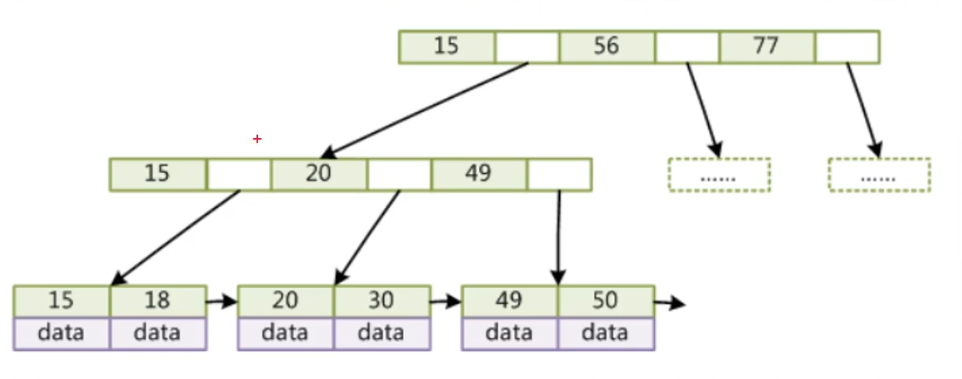
B+Tree(B+树)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
为什么使用B+Tree作为索引的数据结构
索引的优缺点
索引的好处
提高数据检索的效率,降低数据库的IO成本
降低数据排序的成本,降低CPU的消耗
索引的坏处
- 索引需要额外的存储空间
- 在对表进行INSERT、UPDATE和DELETE这些更新操作时MySQL要维护数据索引关系,会产生额外的开销,并且这些更新的操作效率会收到影响
索引分类
按数据列的数量分类
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引
- 复合索引(联合索引):一个索引包含多个列
按类型区分
普通索引
唯一索引
全文索引
空间索引
按数据结构区分
BTree
- 以B树的结构存储索引数据
- 适用于全值匹配(完全匹配)的查询。 class_name=’mysql’ 或者 class_name IN (‘mysql’, ‘bbb’)
- 适合处理范围查找 :between and 、> 、<
- 最左匹配原则:在使用联合索引时,如果只用到了联合索引中的某些而不是所有列进行匹配,则只能从索引的最左侧列开始匹配查找列,如果联合索引中的列都用到了则会忽略顺序,可以命中索引。
BTree索引的限制
- 只能从最左侧开始按索引键的顺序使用索引,不能跳过索引列
- !=、 <> (不等于) 和 NOT IN 操作无法使用索引
- 索引列上不能使用表达式或函数
聚集索引和非聚集索引
Hash结构
Hash索引的缺点和使用场景
索引的建立原则
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引,因为每次更新都需要MYSQL底层维护索引关系
- WHERE条件里用不到的字段不创建索引
- 单值索引与联合索引的选择,在高并发下倾向于创建联合索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组的字段
联合索引的建立原则
- 区分度最高的列放在联合索引的最左侧
- 使用最频繁的列放到联合索引的最左侧
- 尽量把字段长度小的列放在联合索引的最左侧
不适合创建索引的情况
- 表记录太少
- 经常增删改的表
- 某个列如果包含了许多重复内容,建立索引就没有太大的实际效果。索引的选择性= 列的非重复值个数 / 表的行数,计算结果值越接近1则索引的效率越高
使用索引的误区
- 索引越多越好
- 使用IN查询不能用到索引
- 查询过滤顺序必须同索引列顺序相同才可以用到索引
索引失效问题
索引操作
创建
修改
删除
查看


